Agentic Data Engineering is Here
Data engineering is shifting from manual plumbing to agent-driven execution. The grunt work is automated; judgment stays human. • Connect, explore schemas, profile data — automatically. • Stay in your IDE. No context switching, no broken handoffs. • Focus on logic and validation, not copy-paste ETL.

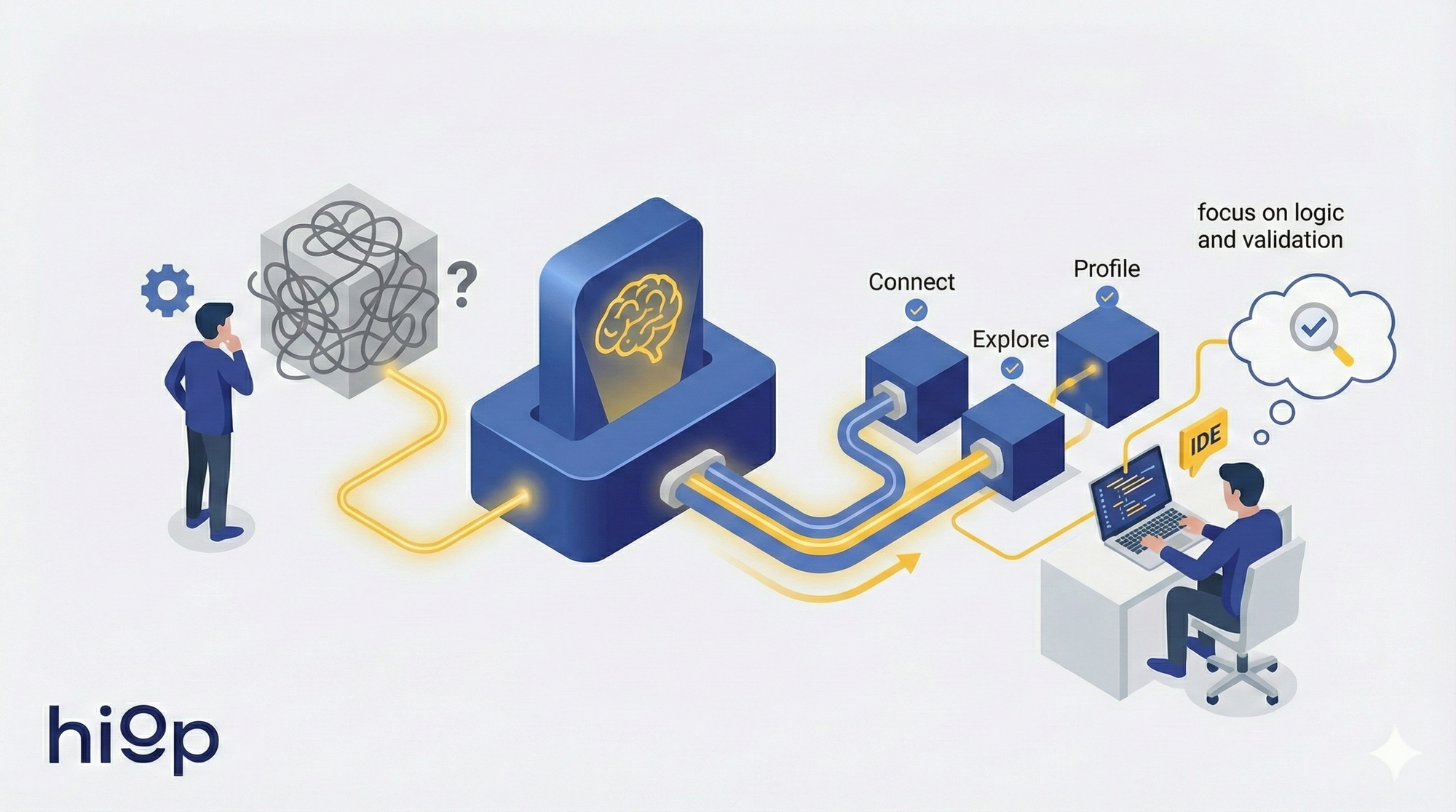
We're witnessing a fundamental shift in how data engineering works. The transition from manual to agentic workflows isn't coming, it's here to stay.
It’s Friday afternoon: you are surfing r/dataengineering and just complaining that, nowadays, any post is either ai slop or marketing or both (we all do). The email arrives. The subject line reads "URGENT".
Fraud detection needed ASAP, cashier operators doing something weird with cash payments. New database to connect, minimal technical documentation – often just the email itself, maybe a connection string. You reach out to the database administrators and get either a 200-page document or two additional lines and a connection string. That's it. Stop. Business requirements are crystal clear, but that’s it.
The agent handles the tedious parts. Establish the connection, explore the database, explore the tables, explore the data inside the tables. The engineer focuses on what requires human judgment: business logic, data architecture, algorithm design, and most importantly, iterating on results. Less time understanding what data you have and how to get it, no need to reach 5 different people to get more information, more time refining what you do with your data.
But this is just the beginning. As agents get smarter, the scope of what they can autonomously handle expands. Today, it's exploration and building the skeleton for pipelines structure. Tomorrow? End-to-end pipeline implementation with minimal supervision. The day after? Autonomous pipelines monitoring, fixing and optimization.
The paradigm is shifting. Data engineering is becoming less about writing copy-paste ETL code or manual queries to figure out what’s actually inside those tables, and more about defining requirements and validating agent-generated solutions. The code is still there. The pipelines are still there. Data models are still there. But how are they created? How will they be monitored and, eventually, fixed? That's changing.
Read this article to see how we solved this in one day.
The Agentic Revolution in hiop: Same Challenge, Different Approach
So how does this work with hiop? Let's dive into what makes agentic data engineering with our platform fundamentally different.
Enter Jump's Backpack Preview, a feature that fundamentally changes how data engineers interact with new data sources. The game-changer? You can query data sources and perform complex ETL dry runs directly from your local IDE. No complex setup. No context switching. No jumping between tools. Just a fast rust CLI interface, an agent-native declarative YAML+SQL framework for data engineering and a vscode extension.
The agent becomes your autonomous data explorer. It can explore databases, understand schemas, analyze data distribution, and identify bottlenecks—all independently. With MCP (Model Context Protocol) and LSP( Language Server Protocol) integration, the agent works seamlessly with AI-powered IDEs like Cursor, making it a natural extension of your development environment.
But here's where it gets interesting—and where Jump's approach differs fundamentally from what we're seeing in the industry.

The Native Advantage: Why IDE-Native Backend Matters
Industry giants are releasing SDKs, MCPs and specialized frontend agents daily. Task-specific agents that accelerate workflows. An agent in a notebook that can explore data and find interesting patterns. These are powerful tools, and they're making a real difference.
But there's a fragmentation problem.
In the traditional agent approach, here's what happens: The agent in your notebook explores the data and finds interesting patterns. Great. Another agent understands pipeline dependencies. But then you need to switch contexts. You manually transfer what you've learned to another agent or tool. You move to a different environment to build your pipelines. The context is lost. The handoff is manual. Information gets lost in translation.
Jump's approach is different. The backend is natively designed for agentic IDE workflows. This means one-shot execution: the agent explores, analyzes, tests AND builds production pipelines in the same IDE context. No context switching. No manual handoffs. The agent maintains full context from exploration to production.
This is the real power: not just having agents, but having a platform where agents can operate end-to-end seamlessly. The agent that explored your database is the same agent that builds your pipeline structure. It remembers what it learned. It applies that knowledge directly. It's not just acceleration, it's a fundamentally different way of working.
The promise? What if the agent could explore, understand, and build the foundation in one hour instead of days, all without leaving your IDE?
Ready to transform your data engineering workflow? Explore Jump's Backpack Preview and see how agentic data engineering can accelerate your team's productivity.