Case Study | 36x faster data exploration with hiop Backpack Preview + jump LSP: Fraud Detection in 1 Hour (Plus 7 Hours of High-Value Work)
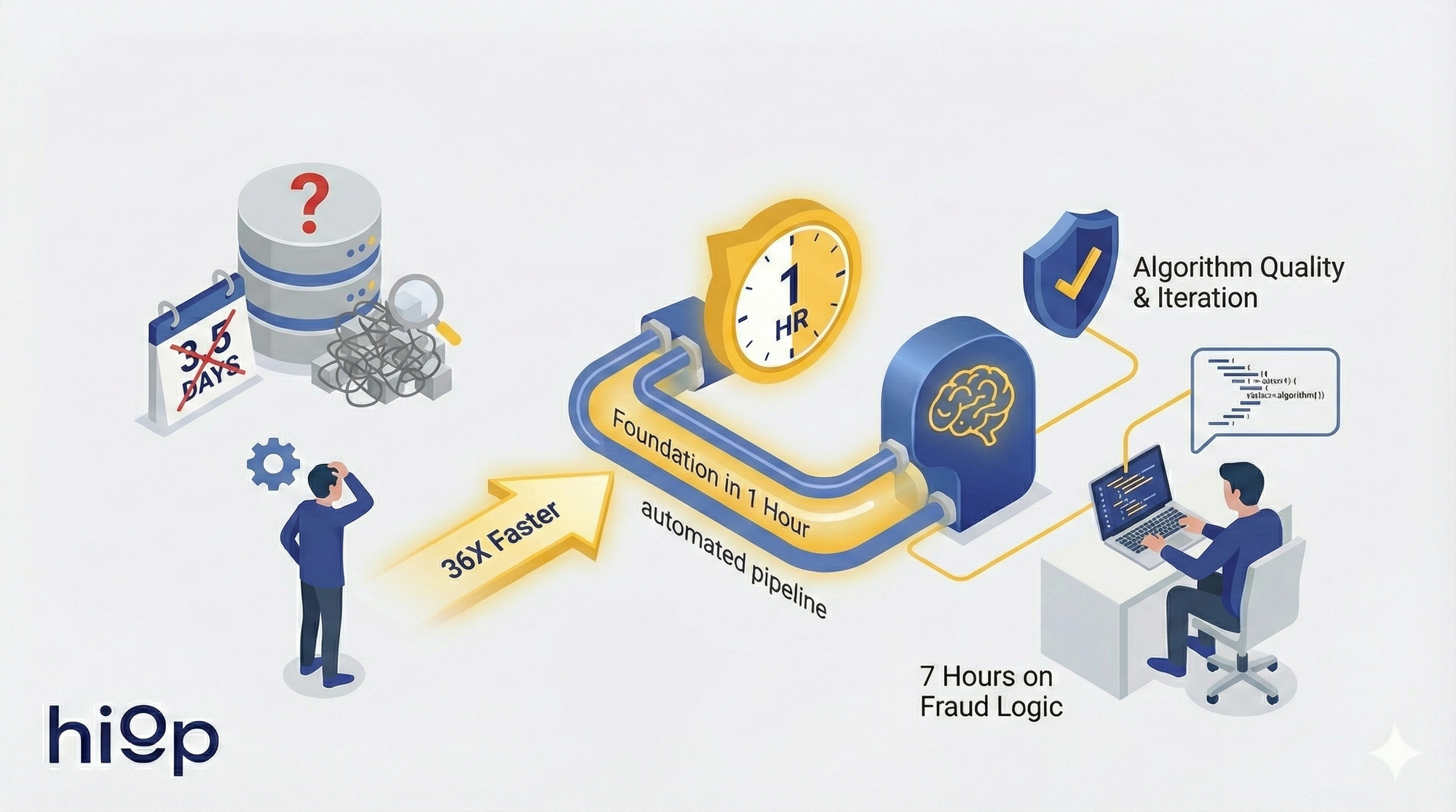
Fraud alert. New DB. No docs. 1 hour to foundation, 7 hours on real fraud logic. • 36× faster exploration: schema, joins, distribution analyzed automatically • Data-driven pipes built in-IDE, production ready • Engineer focuses on algorithm quality and deployment

This is an amazing case a Hiop Developer solved.
In one hour, I built a complete pipeline foundation for a fraud detection system. What traditionally takes half a week of manual exploration – connecting to databases, understanding schemas, discovering relationships, keys and indexes, analyzing data inside the tables. Then, I spent the next seven hours actually building, iterating and deploying on the algorithm itself, with the agent reviewing results, distinguishing fraudulent transactions from system operations, ask for human feedback and performing deep dives on request.
When everything looked good, I had everything I needed to deploy the first version of the algorithm.
Here's the scenario: Friday afternoon, urgent email arrives. Fraud detection needed, cashier operators doing something weird with cash payments. New database to connect, minimal documentation—just the email itself, maybe a connection string. Usually, I reach out to the database administrators and get either a 200-page document or two additional lines. That's it. Stop. In the traditional world, this requires me half a week of manual exploration just to understand what I can find inside the box and how I can retrieve it. I haven't even started thinking about the algorithm, which is what actually brings value in this story.
But with agentic data engineering and leveraging Jump's new feature “Backpack Preview”, everything changes. The agent handles the plumbing. I handled the intelligence.

The Agent Takes Over: Foundation in One Hour
The Exploration Phase (~20 minutes)
The agent autonomously explored both databases. It retrieved schema information, understood table relationships, identified key entities (transactions, users, payment methods, timestamps, cashier operations). It mapped out the data landscape without human intervention. No manual queries. No trial and error. The agent systematically explored, building a mental model of the database structure.
The Architecture Phase (~10 minutes)
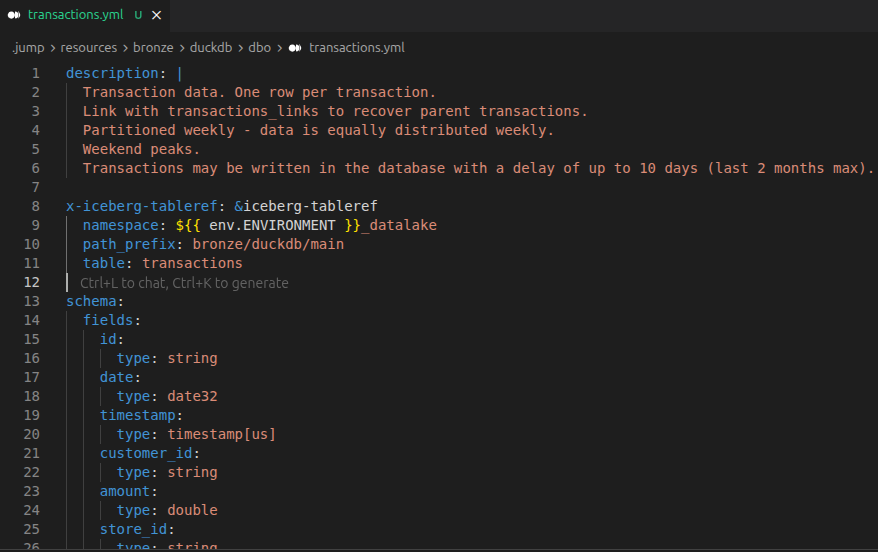
The agent built the initial pipeline skeleton. It created the bronze layer for raw data ingestion. It identified partitioning strategies based on schema analysis. It created resource and itinerary structures, respectively the pieces of the data model and the ETL pipelines, for all relevant tables. It duplicated patterns intelligently across similar tables. The structure is there, ready to be refined.
The Analysis Phase (~30 minutes)
This is where the breakthrough happened. The agent queried actual data, not just the schema. It discovered real data distribution patterns. It identified optimal join keys by analyzing actual relationships in the data. It understood data quality issues. It fine-tuned the structure based on real data insights. It enriched descriptions with actual findings: "Partitioned weekly - data is equally distributed weekly. Weekend peaks. Transactions may be written in the database with a delay of up to 10 days (last 2 months max)."
This is the critical difference. The agent didn’t just look at the schema and make assumptions. It analyzed the actual data. It made data-driven decisions about partitioning, join strategies, and data quality handling.
The Foundation is Ready
In one hour, I had:
- A complete pipeline skeleton ready for fraud detection logic implementation
- Insights
- Data-driven architecture decisions (partitioning, join strategies) based on actual data analysis, not assumptions
- Clear understanding of how to orchestrate and move this to automation
The technology stack? Jump's Backpack Preview, a feature that fundamentally changes how data engineers interact with new data sources, + Cursor auto-model + Jump LSP. This demonstrates that even without Jump MCP, the foundation is powerful. LLMs are pretty good working with plain SQL + Yaml file, because they are schematic. With MCP, it becomes even more seamless and integrated, having the possibility to leverage internal guides, use cases and best practices.
The Real Work Begins: Iterating on Results
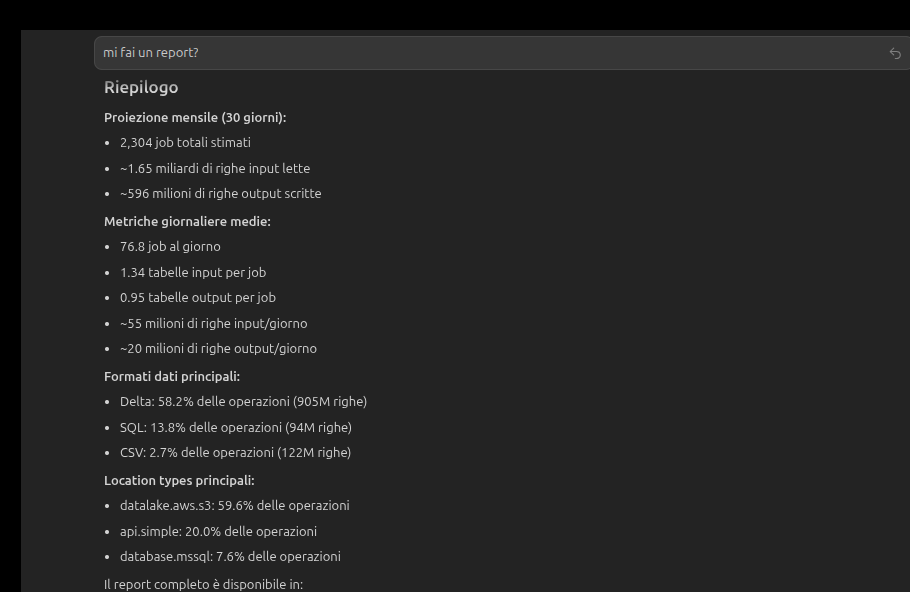
Now comes the part that matters: building and refining the fraud detection algorithm and put everything in a daily pipeline. I thought through the logic, and the IDE built it. I reviewed examples of transactions identified as fraudulent. The agent reviewed the output file and indicated which ones seemed genuinely fraudulent versus which appeared to be system operations or legitimate edge cases.
I could ask for deep dives: "Can you check if there's a causal code field in the database and how it's populated? Can we exclude certain transactions from the report based on that?" The agent explored the database, found the field, analyzed its values, and suggested how to filter transactions.
I iterated and refined, testing different thresholds. I asked the agent to analyze patterns in the false positives. I asked it to check if there are other fields that could help distinguish fraudulent transactions from legitimate ones. The agent maintained full context: it remembered what it learned during exploration, what it found during analysis, and what we’ve discovered during iteration. Just me, a strong coffee, hunting down 200 reasoning steps flying by at warp speed. Hawk mode: ON.
This is where the real value is created: not in the initial exploration (though that's essential), but in the iterative refinement of the algorithm based on actual results. The agent handled the data plumbing, so I could focus on the intelligence. Together, we built something that works and scales quickly.
Why This Changes Everything
What does this mean for data engineering as a discipline?
Speed: From half-week long exploration to one-hour autonomous discovery and foundation-building. That's roughly 36x faster on exploration alone. But it's not just about speed, it's about what you can do with that time. Instead of spending a week understanding the data, you spend one hour, and then you have seven hours to focus on what actually matters: building and iterating on the fraud detection algorithm and reporting key relevant results from the first iteration. That’s a solid 5x performance on iteration, deployment and reporting with respect to traditional fragmented stack + chatbot assistance.
Quality: Data-driven architecture decisions vs. educated guesses. When the agent analyzes actual data distribution, join cardinalities, indexes optimizations and actual data quality issues, the decisions are better. Fewer production surprises. Fewer performance issues. Fewer iterations. The final executive report has the full-context, quality is higher.
Autonomy: The agent explores, learns, and adapts independently. Engineers become orchestrators, not manual laborers. You define the goal—"build a fraud detection pipeline for this database", maybe attach a report from business that clearly indicates the expected results and the scoping, and the agent figures out the how. You validate. You refine. But you're not doing the grunt work. It’s the autonomous junior you asked for a couple of months ago, except your boss never actually hired them. On steroids.
Scalability: Engineers focus on business logic and algorithms, not on prep work. The bottleneck shifts from "understanding the underlying systems" to "iterating on results and refining algorithms".
The Competitive Edge: Organizations that adopt this move faster, make better decisions. They can experiment more. They can fail faster and learn faster.
The Shift: We're moving from "data engineers who code" to "data engineers who architect and guide agents." The role evolves. The value shifts. But the impact? Exponential.
Conclusion: Your Next Friday Afternoon
Imagine your next Friday afternoon email. The same urgent request. The same new database. The same minimal documentation.
But this time, your response is different. Instead of "This will take a week to explore and understand," you say: "Let me have the agent explore this. I'll have the foundation in an hour, and then I'll spend the rest of the day building and iterating on the algorithm. I’ll deploy algorithm v1 and provide a report with main findings by Monday EOD."
The engineer's role evolves: from explorer to validator, from coder to architect, from data archaeologist to algorithm designer. You're not doing less—you're doing more of what matters. You're focusing on the fraud detection algorithm and iterating on results, not the data plumbing.
This is agentic data engineering. This is the future. And with Jump's Backpack Preview, it's available today.
Experience the power of Jump's Backpack Preview. Turn your next "new database" challenge into a one-hour foundation-building exercise, then spend your time where it matters: iterating on results and refining algorithms. Because agentic data engineering isn't just the next big thing—it's the thing that's going to change how we build data systems.
Ready to transform your data engineering workflow? Explore Jump's Backpack Preview and see how agentic data engineering can accelerate your team's productivity.