Snowflake + Apache Iceberg: Build an ML-Powered Lakehouse with Hiop
Use Hiop to centralize ingestion on your datalake with Apache Iceberg open data format, keep the lake as the source of truth, and let Snowflake do what it does best: analytics, ML, and high-value data serving.

Snowflake is excellent at analytics, machine learning, and serving curated datasets to BI and business teams. The wrong conclusion is that it also needs to be the place where every raw table from every operational system lands first. That pattern works, but it comes with a tax. You duplicate raw data into the warehouse, keep another storage layer synchronized, and spend warehouse compute on jobs that are mostly plumbing. The more sources you add, the more expensive and fragile that pattern becomes.
There is a cleaner approach.
Use Hiop to centralize ingestion and transformations on an Apache Iceberg data lake. Keep that lake as the single source of truth. Then use Snowflake where it creates the most value: analytics, machine learning, and serving curated datasets to the business. Then, again, use Hiop to decentralize data to your external systems and extract the most possible value from your data.
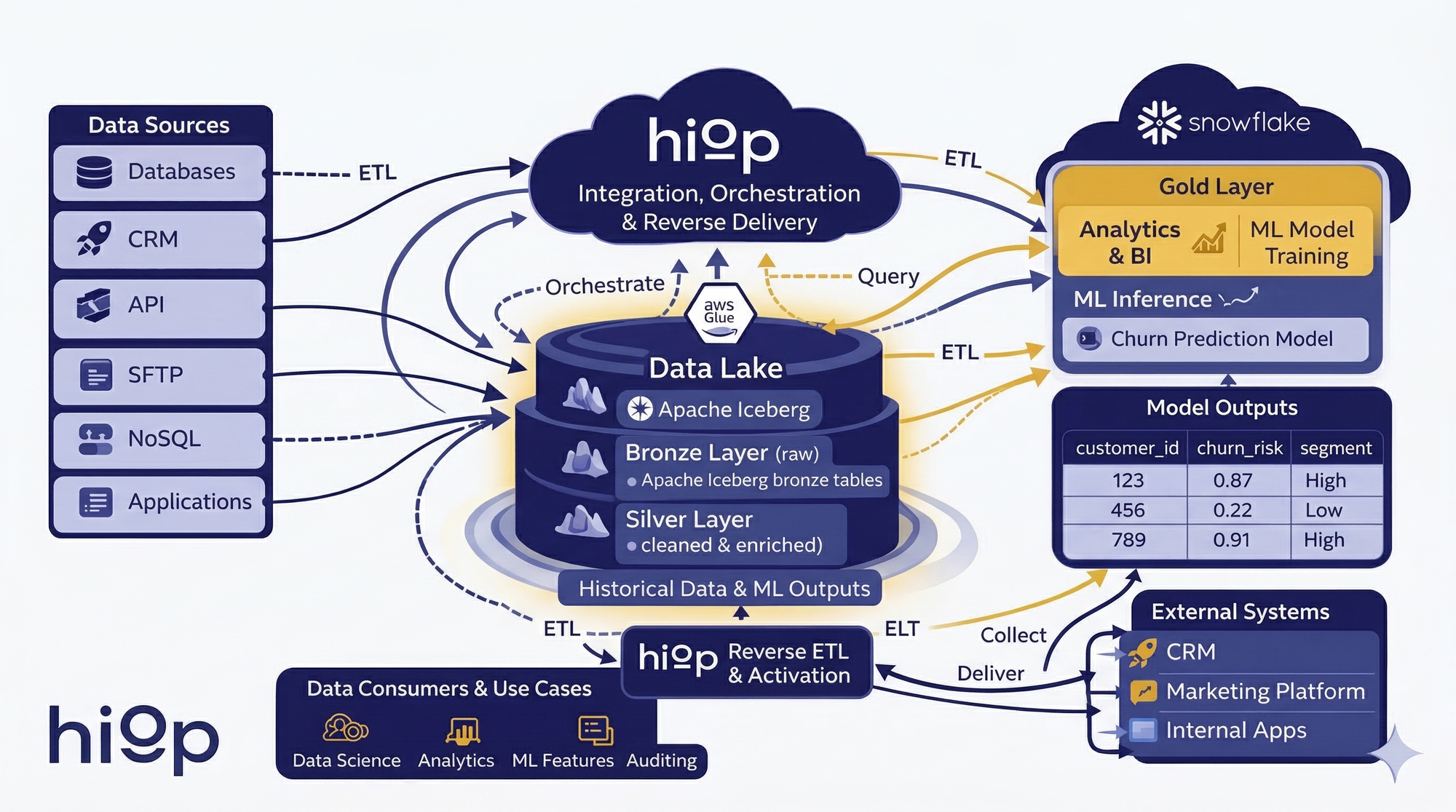
Architecture at a glance
Operational sources → Hiop Jump → Bronze and silver in Apache Iceberg (cataloged in AWS Glue) → Hiop Jump → Snowflake for gold, analytics, and ML → Hiop Jump → CRM and other external systems
Stop ingesting every raw dataset into Snowflake
Snowflake is powerful. Raw duplication is still a tax.
Snowflake is a strong platform for analytics, governed data sharing, BI workloads, and ML execution. That is exactly why it should sit higher in the stack.
When the warehouse also becomes the permanent home of every raw feed, it inherits work that does not justify warehouse-level spend: broad ingestion, raw persistence, large-volume transformations, constant synchronization across operational systems, continuos maintainance and optimization.
The result is familiar. Teams pay for a premium analytics platform, then use a large part of it to solve ingestion problems and to clean raw data.
The data lake should stay the unified Open source of truth
A more durable pattern is to keep raw and refined operational data in the lake, in an open format, and let multiple engines work from that shared foundation.
In this setup, the lake remains the system of record. Bronze data lands there first. Silver data is written there after standardization and enrichment. Snowflake reads the data it needs and serves the layers that are most useful for analytics, ML, and business consumption.
That changes the role of the warehouse. It stops being the first stop for every dataset and becomes the place where high-value work happens.
Your most valuable Data Scientists should still have an easy cheap way to inspect raw data
Snowflake can query Iceberg tables directly from metadata, refreshing at runtime without duplicating data into the warehouse. At the same time, Iceberg handles filter pushdown, metadata pruning, and file optimization under the hood—so queries actually scan what’s needed.
The result is simple: data scientists can explore bronze and silver data directly, without worrying about table tuning, warehouse configuration, or runaway query costs. No copies, no friction—just fast, safe iteration where it actually matters. Moreover, data is stored
The reference architecture: Hiop, Snowflake, and Apache Iceberg
Hiop Jump centralizes ingestion into the lake
Hiop Jump connects to the systems that actually produce data: transactional databases, CRMs, APIs, SFTP drops, and NoSQL stores. It lands those feeds into the lake as bronze Iceberg tables.
AWS Glue acts as the shared catalog, keeping those Iceberg tables discoverable and governed across the stack or across multiple engines.
This matters for one reason above all: the raw layer has one home. Your data isn’t trapped inside one proprietary system. Instead, it lives in open file formats (like Apache Parquet) and is managed by an open, vendor-neutral metadata layer (Apache Iceberg).
Hiop transforms bronze into silver (and eventually gold) with serverless compute
Once the raw layer is in place, Hiop handles the heavy transformation work with serverless compute and writes the results back to the lake as silver Iceberg tables.
That gives teams a clean split:
- Bronze for raw, source-aligned data
- Silver for standardized, enriched, analysis-ready data
- Gold for business-facing datasets, metrics, and ML-ready outputs
The costly and data-intensive part of the stack stays off the warehouse, without turning the lake into an unmanaged mess.
Snowflake becomes the analytics and ML layer
From there, curated datasets can be served to Snowflake for the jobs Snowflake is especially good at:
- fast SQL analytics
- BI-facing gold tables
- governed data serving
- model development
- inference workflows
That is the right division of labor. Hiop owns the operational data movement, transformation layer. Snowflake owns the intelligence layer. Hiop serves data insights to external applicatives (e.g. CRM).
The ML use case: customer churn prediction
This architecture becomes much more interesting when you move beyond dashboards.
Imagine a company that wants to predict churn. Customer data lives in multiple systems: product events, billing, support, CRM, and account data. Management hires a new data scientist and asks for a churn prediction model so marketing can run retention campaigns based on predicted risk.
This is where many teams make the same mistake: the data scientist ends up doing data engineering.
A data scientist should not have to rebuild ingestion
A churn model rarely starts from gold tables alone.
Gold is useful when the question is already settled. A data scientist, especially early in model development, usually needs more than that. They need silver at a minimum, and sometimes bronze as well. They need to inspect low-level events, test hypotheses, compare feature candidates, and work backwards from the business outcome they are trying to predict.
That work is valuable. Rebuilding ingestion pipelines is not. With this architecture, the data scientist can explore the relevant bronze and silver data orchestrated and transformed by Hiop Jump in Apache Iceberg format directly from your S3, without needing to copy raw datasets into the warehouse just to begin.
Data scientists might also want to use more flexible tools, like local Python notebooks with DuckDB or Spark. When you choose Apache Iceberg, integration is seamless: your data is and will still stored in an Open format and can be explored from anywhere. Including Snowflake, of course.
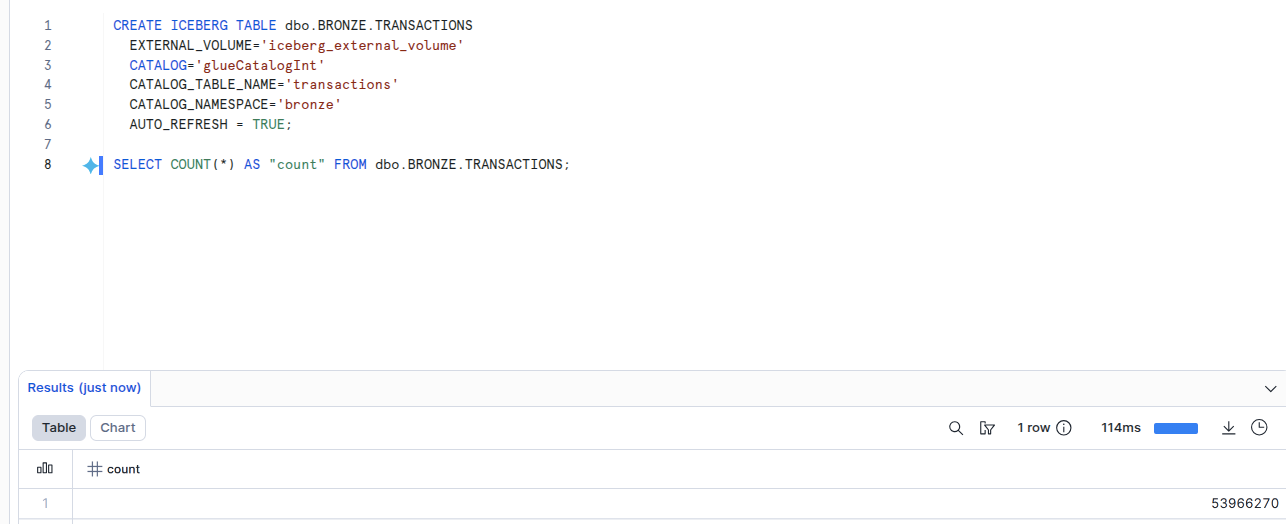
Hiop orchestrate the feature dataset pipeline
Once the data scientist identifies the right features - say usage decline, payment delays, support ticket patterns, contract changes, and engagement drop - Hiop can orchestrate the daily feature pipeline.
It aggregates the required inputs from multiple sources, applies the necessary transformations, serves the inference dataset to Snowflake on schedule or external triggers and pings snowflake to perform the inference.
The important point is not just that the data arrives. It is that the orchestration is owned by the platform layer, written in human-readable (these days we could say also agent-readable) YAML + SQL files, not by a growing pile of custom python scripts.
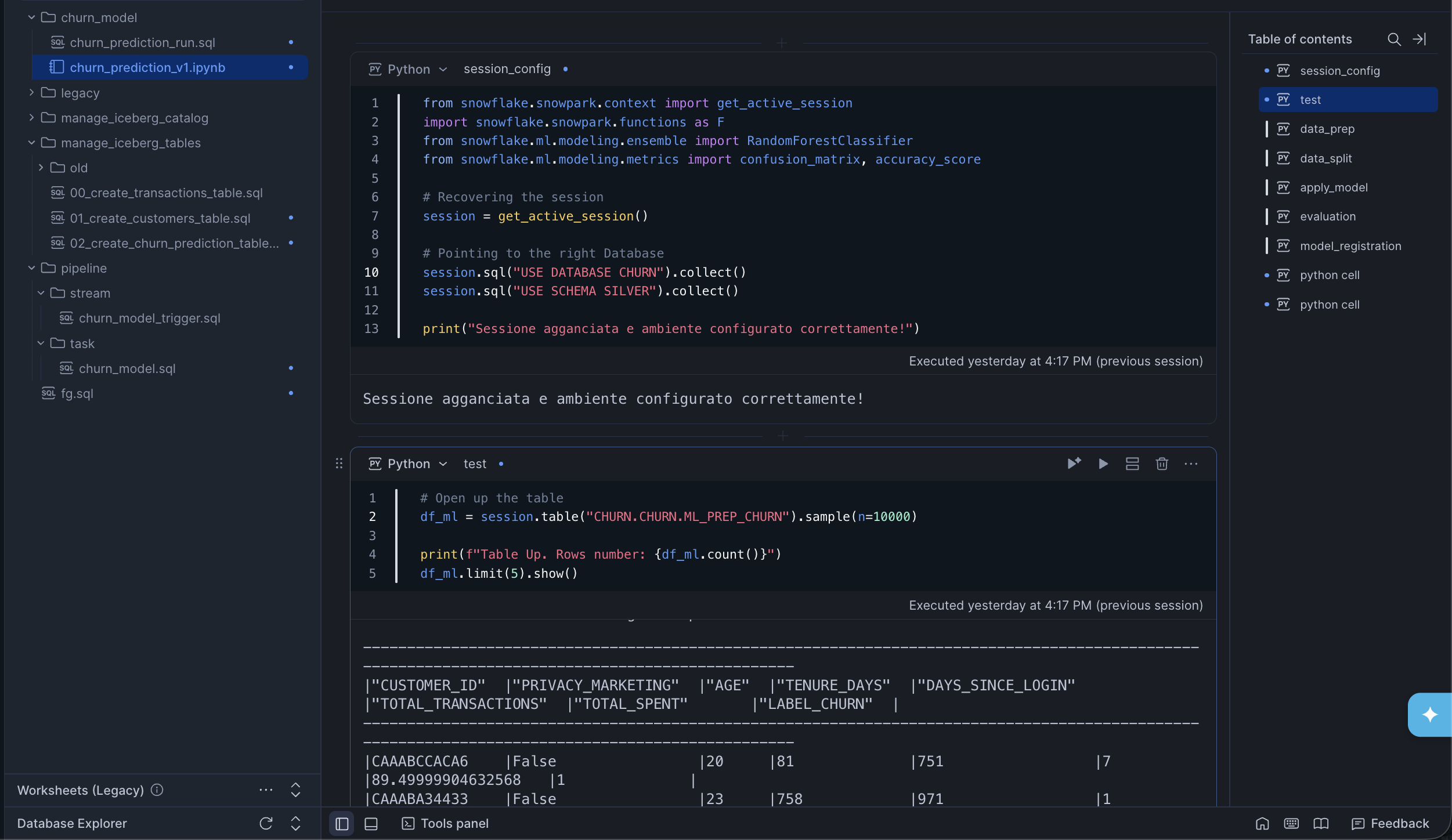
Snowflake runs the model
Snowflake then executes the model and produces a result such as:
customer_idchurn_risk_probabilitychurn_risk_cluster
That is exactly the kind of workload Snowflake should handle. Analytical compute. Model execution. Controlled serving of useful outputs.
Hiop closes the loop back to the business
A churn score sitting in a warehouse table is not a business outcome.
Hiop gets triggered, picks up the model output and turns it into something operational:
- it (eventually) historicizes the results back into Iceberg so the team can evaluate model performance later
- it tags or versions the output so it is clear which model produced it
- it dispatches the result to external systems, such as the CRM
Now the marketing team can run retention campaigns by churn_risk_cluster, customer success can prioritize outreach, and the business can act on the result without manual exports. That is the real value of the architecture: it closes the loop.
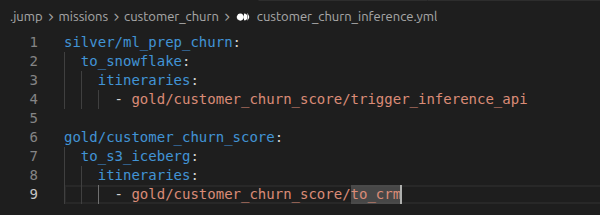
What Hiop really adds here
Hiop Jump is not just a smooth integration layer with Snowflake services. It is the serverless operational system that connects your data silos and makes the architecture usable end to end:
- ingesting data from source systems into the lake
- running serverless transformations for bronze, silver and (eventually) gold layer
- handles you Iceberg tables
- orchestrating feature datasets for ML workflows
- picking up model outputs
- pushing results into external systems
You already use Snowflake, but the bill is climbing
Maybe ingestion works today with dbt, Fivetran, custom scripts, or a mix of tools. The problem is that too much raw and transformation work is still happening inside the warehouse.
Offloading bronze and silver processing to Hiop is a cleaner way to use Snowflake and often a cheaper one.
Adopting Apache Iceberg data format gives you full ownership of your data.
You want Apache Iceberg Open Storage without running the project yourself
Iceberg is compelling because it keeps the lake open and interoperable and offers several powerful state-of-the-art features for lakehouse data. But few teams want to own the surrounding operational burden: catalogs, infrastructure, dependency drift and pipeline maintenance, especially in a fast growing environment as Apache Iceberg.